
누적 확률(Cumulatedistribution function) 누적 확률 함수는 이산 확률 변수(discretter andomvariables) X에 대한 함수로 다음과 같은 식으로 표현된다.여기서 이산 확률 변수가 아닌 연속 확률 변수로 개념을 확장시키면 누적 확률은 확률 밀도 함수의 적분 값과 같아진다.
이산 확률 변수에서 평균과 분산 평균(mean)은 기대치이며 변수 X를 무작위로 추출했을 경우 평균적으로 나올 것으로 기대되는 값이다.
다음과 같은 식을 통해 표현할 수 있다.분산(variance)은 표준 편차의 제곱이며 다음과 같은 식으로 표현할 수 있다.제곱의 평균에서 평균 제곱을 뺀 값이 분산되며, 이 값은 표준 편차(standard deviation)의 제곱이 된다.
표준편차 표준편차란 평균적으로 평균에서 얼마나 떨어져 있는가?를 나타내는 값으로, 이 값이 클수록 데이터가 평균에서 멀리 떨어져 있는 균등한 분포를 나타내고 표준편차가 작을수록 평균에 값이 편중되어 있는 분포를 나타낸다.
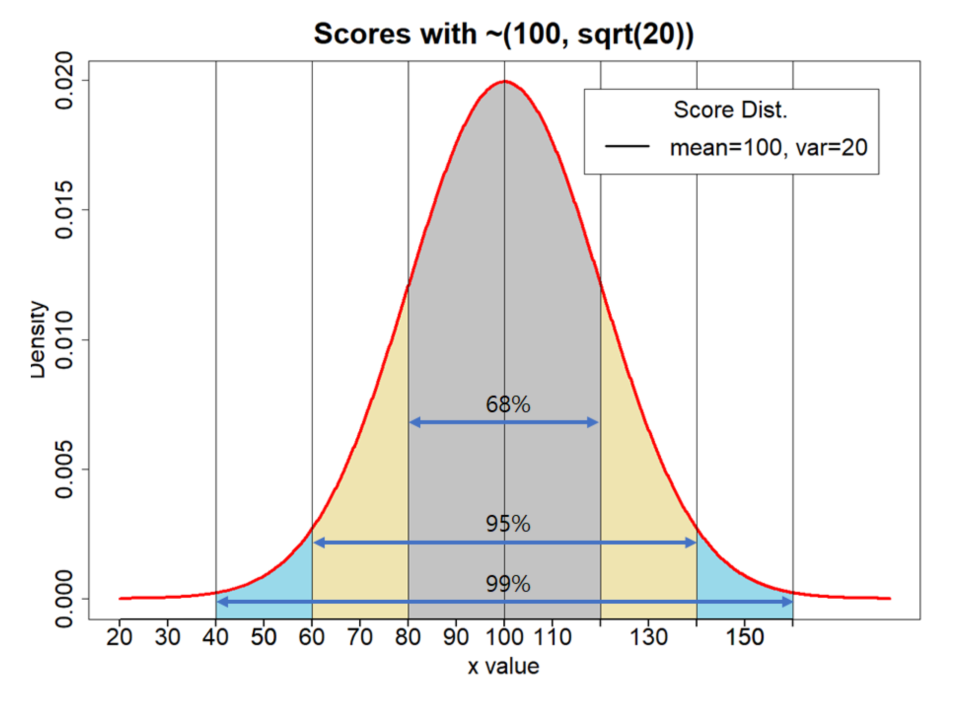
표준 정규분표의 경우 평균을 기준으로 1 시그마분 좌우에서 차지하는 영역을 보면 전체의 68%를 차지하는 것을 볼 수 있다.
일반적으로 분포하는 데이터의 수가 30을 넘으면 정규 분포(normaldistribution)를 만족한다고 가정할 수 있다.
이걸 일상생활에서 응용해보면 내가 이번 1학기 생산공학 수업에서 82점을 받았고 평균이 70점, 표준편차가 10점이라고 해보자.수강생이 48명이기 때문에 학생들의 성적이 표준 정규 분포를 따른다고 가정하면 제가 82점으로 평균이 70점이기 때문에 두 사람의 차이는 12점입니다.표준 편차가 10이므로 1 시그마 조금 밖에 내 점수가 위치하는 것을 알 수 있다.
따라서 내 점수는 상위 16% 이내가 되고 교수 학점 비율에 대한 정보가 A+:~상위 20% A0:~상위 40% B+:~상위 60%라는 사실을 안다면 기말에 지금과 같은 기조를 유지하면서 공부하면 A+까지 노릴 수 있다는 결론이 나온다.
다만 보정을 조금만 해보면 학생들의 성적은 보통 편향된 분포를 보이므로 실제 80점을 받은 (점수가 평균 1시그마치 차이가 나는) 학생의 경우 상위 16%보다 낮은 분포에 위치할 수 있으므로 실제 상황에서의 적용은 다소 보수적으로 생각해야 한다.
베르누이 분포(Bernouli Distribution) 베르누이 분포는 결과가 단 2진이고 결과에 대한 확률이 일정할 경우 적용된다.예로는 동전 반환 등이 있다. 베르누이 분포는 다음과 같이 표현할 수 있다.
아래 수식으로 보아 연속 확률로 오해해서는 안 된다. x의 범위를 0과 1의 두 숫자로 제한해 두었기 때문에 그래프를 그렸을 때 연속적으로 표현되지 않는 상황이다.
베르누이 분포에서의 평균과 분산은 다음과 같다.상기와 같이 베르누이 분포에서의 평균과 분산을 정의할 수 있다.
이항 분포(Binomial Distribution) 이항 분포(binomial distribution)는 간단히 말해 베르누이 분포 실행을 독립적으로 여러 번 반복한 것이다.
동전은 계속 던지고 주머니 속의 공은 한 번 빼내 같은 시행을 반복한 상황에서 분포한다. 이때 무작위 변수 X는 전체 n회 시행으로 특정 사건이 일어난 횟수와 같아진다. 따라서, X의 범위는 0에서 n까지 제한되며 다음과 같은 식을 통해 확률 질량 함수로 표현 가능하다.
이항 분포는 n과 확률 p가 변수가 되며 B(n, p)의 기본형으로 표현된다. 이항 분포에서의 차원(dimension)은 횟수가 되므로 앞의 베르누이 분포 차원(확률)에 전체 시행 횟수를 곱산한다.따라서, 이항 분포에서의 평균과 분산은 다음과 같다.